


Für Neueinsteiger in das AWS Well-Architected Framework mag das Konzept der Operational Excellence etwas vage erscheinen. Ist "Exzellenz" nicht einfach etwas, das wir ständig anstreben, oder schlimmstenfalls eine allgegenwärtige Phrase, die durch übermäßigen Gebrauch ihre Wirkung verliert? Nun, im Zusammenhang mit der AWS-Cloud hat er eine ganz bestimmte Bedeutung und spielt eine wichtige Rolle.
Stellen Sie sich vor, Sie sind der Vorarbeiter eines neuen und spannenden Bauprojekts, und die Baustelle ist wie die digitale Landschaft, mit viel Potenzial, aber auch vielen Hindernissen. Ihr Team mag aus erfahrenen Handwerkern bestehen, die ihr Handwerk verstehen, aber ohne einen gut durchdachten Plan und klare Sicherheitsregeln können Sie nicht erwarten, dass alles reibungslos abläuft.
Viele Cloud-Unternehmen stehen zudem vor einer Reihe komplexer Herausforderungen, anstatt eine einfache und offensichtliche Aufgabe vor sich zu haben. Selbst mit einem fähigen Team und den richtigen Tools kann die Vielfalt der Probleme und Möglichkeiten einschüchternd wirken. Hier kann das AWS Well-Architected Framework und insbesondere die Säule "Operational Excellence" als verlässliche Blaupause für das Vorankommen dienen und sicherstellen, dass Sie reibungslos und erfolgreich navigieren und mehrere Probleme gleichzeitig bewältigen können.
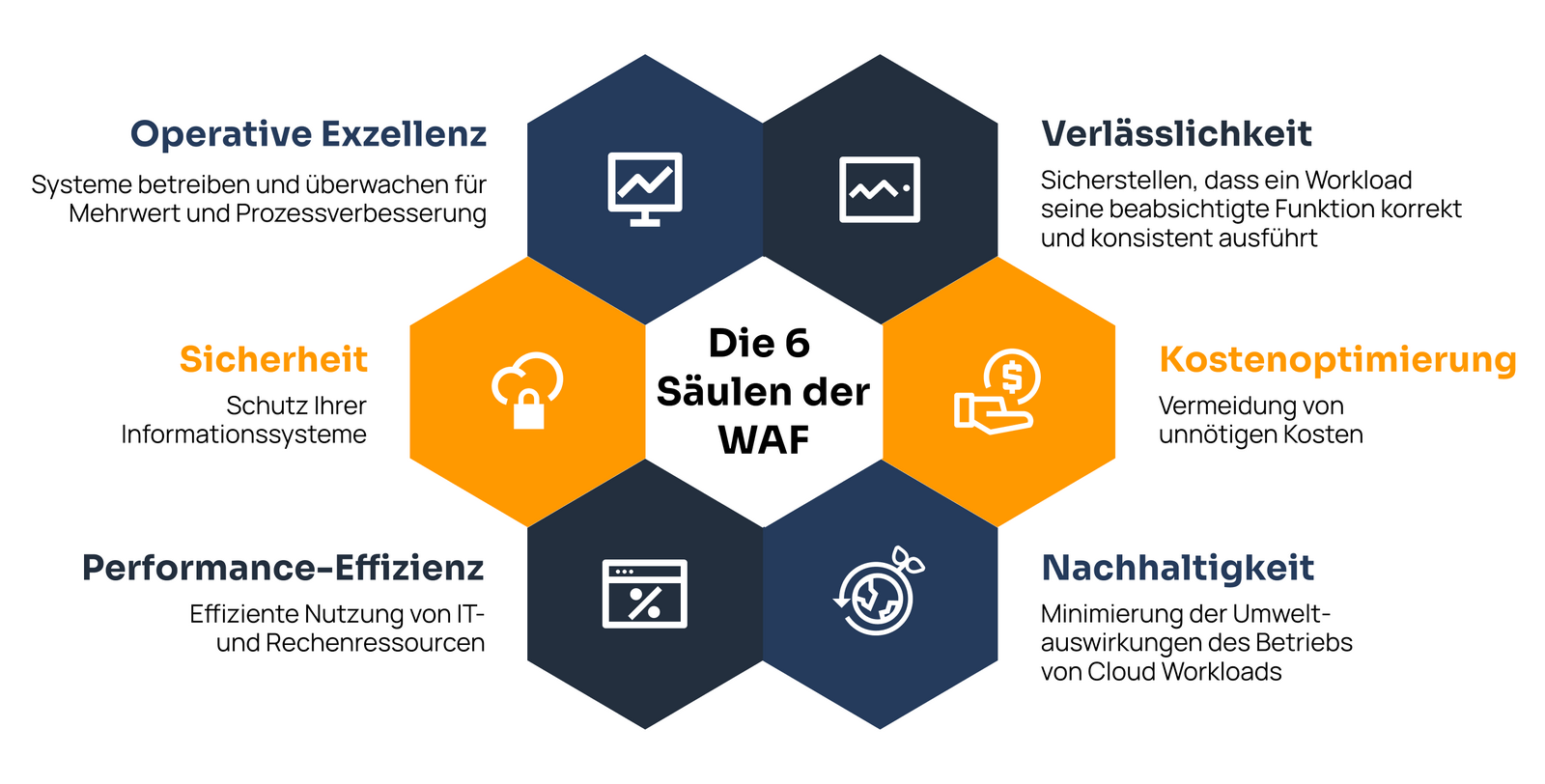
Was ist das Well-Architected Framework?
Einfach ausgedrückt, bietet das AWS Well-Architected Framework Richtlinien für den Aufbau robuster und sicherer Cloud-Lösungen. Die sogenannten "sechs Säulen" des Frameworks befassen sich mit spezifischen Aspekten wie Sicherheit, Kostenoptimierung, Leistungseffizienz, Zuverlässigkeit und Nachhaltigkeit und gewährleisten einen umfassenden Ansatz für die Cloud-Architektur. Die Säule "Operational Excellence" hebt strukturelle Aspekte und die Bedeutung der Verfeinerung von Prozessen zur Optimierung von Geschäftswert und Leistung hervor.
Das Fundament des Erfolgs
Beim Cloud-Betrieb ist eine gut strukturierte und organisierte Grundlage genauso wichtig wie beim physischen Aufbau. Ein solides Fundament aus gut durchdachten Prozessen wirkt sich direkt auf die Fähigkeit eines Unternehmens aus, Dienste zuverlässig und sicher bereitzustellen.
Ebenso schöpft ein guter Cloud-Betrieb sein Budget und seine Ressourcen optimal aus. Er minimiert Redundanzen, optimiert die Ressourcennutzung und fördert die kontinuierliche Verbesserung. Dieser Ansatz fördert auch die Zuverlässigkeit, die proaktive Überwachung, die rasche Lösung von Problemen und robuste Notfallwiederherstellungspläne.
Und so wie ein gutes Bauprojekt eine solide und zuverlässige Struktur liefert, garantiert Operational Excellence, dass digitale Dienste durchgängig verfügbar, reaktionsschnell und sicher sind, was für den geschäftlichen Erfolg im Cloud-Zeitalter unerlässlich ist.
Allgemeine Grundsätze der Operational Excellence
Welche Schritte können Sie also unternehmen, um diese Ziele zu erreichen? Wie immer ist AWS eine hervorragende Wissensquelle für Einblicke und Ratschläge zur Umsetzung der Theorie in die Praxis. AWS erklärt, dass "die Säule Operational Excellence die Fähigkeit umfasst, Entwicklung und Arbeitslasten effektiv zu unterstützen, Einblicke in ihre Abläufe zu gewinnen und unterstützende Prozesse und Verfahren kontinuierlich zu verbessern, um einen geschäftlichen Nutzen zu erzielen" und dass sie darüber hinaus "einen Überblick über Designprinzipien, bewährte Verfahren und Fragen" bietet.
Die Säule AWS Operational Excellence leitet Unternehmen bei der Einrichtung einer robusten Cloud-Umgebung an, indem sie die Bedeutung der Automatisierung von Abläufen, der Durchführung häufiger und reversibler Änderungen und der kontinuierlichen Verbesserung von Prozessen hervorhebt. Sie hilft Unternehmen, Fehler zu antizipieren und aus ihnen zu lernen, um sicherzustellen, dass sie auf verschiedene Szenarien gut vorbereitet sind.
Ein Rezept für Erfolg
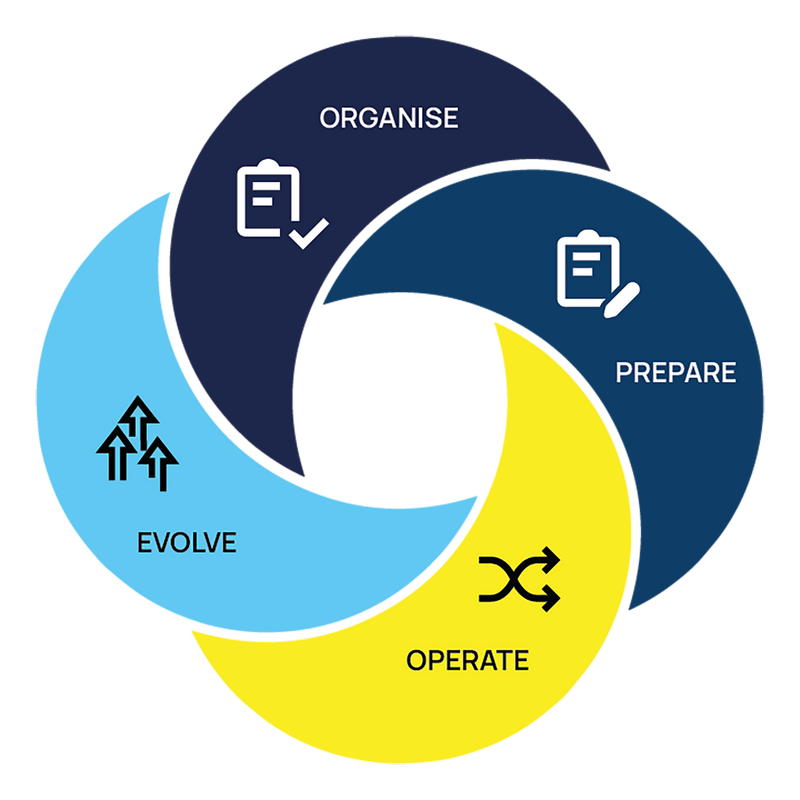
Genauer gesagt gibt es einige klare Aktivitätsphasen und Regeln für die Vorgehensweise, die für die Förderung von Spitzenleistungen in jedem Cloud-Projekt gelten:
- Organisieren: Konzentrieren Sie sich darauf, eine klare Struktur für Ihre Cloud-Umgebung einzurichten, einschließlich Rollendefinitionen und Ressourcenkennzeichnung, um die Verwaltung und Ressourcennutzung zu optimieren.
- Vorbereiten: Entwickeln Sie solide, automatisierte Prozesse für die Bereitstellung und Skalierung, um einen konsistenten und skalierbaren Cloud-Betrieb zu gewährleisten.
- Betreiben: Pflegen und verwalten Sie Ihre Cloud-Infrastruktur effektiv, mit Echtzeit-Überwachung und zuverlässiger Reaktion auf Störungen, um Ausfallzeiten zu minimieren und einen reibungslosen Betrieb zu gewährleisten.
- Entwickeln: Verbessern Sie Ihre Cloud-Einrichtung kontinuierlich, indem Sie die Leistung analysieren, Feedback einholen und sich an veränderte geschäftliche und technologische Anforderungen anpassen.
Diese grundlegenden Phasen der Cloud-Bereitstellung bilden einen umfassenden Fahrplan für operative Exzellenz, und zusammen bilden sie den Rahmen für einen zyklischen Prozess der Verfeinerung im Laufe der Zeit und nicht für ein einzelnes, dramatisches Ereignis. Doch wie sollten Sie Ihren Cloud-Betrieb realistischerweise gestalten, um diese Grundsätze zu einer ständigen Realität werden zu lassen?
5 Gestaltungsprinzipien für kontinuierliche Verbesserung
AWS hat fünf wichtige Designprinzipien![]() für Operational Excellence in der Cloud identifiziert, die die oben genannten Strukturphasen durch spezifischere Ratschläge ergänzen:
für Operational Excellence in der Cloud identifiziert, die die oben genannten Strukturphasen durch spezifischere Ratschläge ergänzen:
- Automatisieren Sie den Betrieb: Behandeln Sie die Cloud-Verwaltung wie die Codierung - automatisieren Sie Aufgaben, um Fehler zu reduzieren.
- Regelmäßige, kleine Updates: Führen Sie häufige, kleinere Aktualisierungen an Ihrem System durch, damit Sie eventuelle Probleme leicht beheben können.
- Kontinuierliche Verbesserung: Verfeinern Sie Ihre Prozesse ständig, passen Sie sie an neue Anforderungen an und testen Sie ihre Effektivität.
- Planen Sie für Ausfälle: Ermitteln und testen Sie mögliche Probleme, um besser vorbereitet zu sein.
- Aus Fehlern lernen: Nutzen Sie Misserfolge als Lernchance und geben Sie diese Erkenntnisse weiter, um den Gesamtbetrieb zu verbessern.

Der letzte Punkt unterstreicht die allgemeinere Wahrheit, dass die kontinuierliche Verbesserung der Eckpfeiler der operativen Exzellenz ist. Dieser Grundsatz untermauert, wie wichtig es ist, sich parallel zum technologischen Fortschritt weiterzuentwickeln, und zwar durch einen stetigen Fortschritt kleiner, inkrementeller Veränderungen und durch die Pflege einer Kultur des kontinuierlichen Wachstums und Lernens.
Auf diese Weise können Unternehmen im Laufe der Zeit bemerkenswerte Fortschritte in Bezug auf Leistung und Innovation erzielen, wobei das kollektive Streben nach Spitzenleistungen in substanziellen Verbesserungen gipfelt, die die Art und Weise, wie Sie arbeiten, neu definieren.
Beispiel-Szenarien: Wir sind alle Individuen!
Lassen Sie uns einige hypothetische Beispiele betrachten, um zu zeigen, wie die Dinge in der Praxis ablaufen könnten:
- Online-Händler - Kosteneffizienz durch optimierte Abläufe: Stellen Sie sich einen Online-Händler vor, der seinen Cloud-Betrieb aus Gründen der Kosteneffizienz optimieren möchte. Durch die Umsetzung von Operational Excellence-Prinzipien werden redundante Prozesse identifiziert, die Ressourcenzuweisung durch Cloud-native Services optimiert und Routineaufgaben automatisiert. Dieser strategische Ansatz führt zu einer Senkung der Betriebskosten um etwa 30 % bei gleichzeitiger Verbesserung der Reaktionszeiten und Skalierbarkeit.
- Softwareentwicklungsunternehmen - Verbesserte Zuverlässigkeit und Skalierbarkeit: Stellen Sie sich ein Softwareentwicklungsunternehmen vor, das in Zeiten hoher Auslastung mit Ausfallzeiten zu kämpfen hat. Mithilfe von Operational Excellence-Strategien strukturiert es seine Infrastruktur um und nutzt Cloud-Dienste für die automatische Skalierung und die Notfallwiederherstellungsplanung. Automatisierte Überwachungs- und Skalierungsmechanismen führen zu einer verbesserten Zuverlässigkeit, die einen unterbrechungsfreien Service bei Nachfragespitzen gewährleistet und Ausfallzeiten um bis zu 40 % reduzieren kann.

Vergessen wir jedoch nicht, dass jede Situation anders ist, und während diese Beispiele zur Veranschaulichung dienen, bietet jedes Szenario einzigartige Herausforderungen und Möglichkeiten. Ja, es ist wahr - wir sind alle Individuen! Genau aus diesem Grund sind das Well-Architected Framework und die Designprinzipien so nützlich. Wenn Sie sich diese zu eigen machen, können Sie Ihre eigenen Kostenmuster besser optimieren, bestimmte Bereiche der Zuverlässigkeit stärken und effizient skalieren, um Ihrem individuellen Kontext gerecht zu werden.
Machen Sie sich bereit, Ihr Cloud-Potenzial freizusetzen.
Wie Sie sehen, ist operative Exzellenz eine wichtige Komponente des Cloud Computing, und das AWS Well-Architected Framework bietet eine solide Grundlage für Verbesserungen. Wenn Sie diese Richtlinien befolgen und die entsprechende Unterstützung in Anspruch nehmen, können Sie hoffentlich erste Schritte zur Erreichung Ihrer Ziele unternehmen - und einen effizienteren, kostengünstigeren Cloud-Betrieb erreichen!
Das könnte Sie auch interessieren
- AWS Well-Architected
 (AWS Guide)
(AWS Guide)